[Paper Review] A Large Language Model Enhanced Conversational Recommender System

![[Paper Review] A Large Language Model Enhanced Conversational Recommender System](https://storage.ghost.io/c/10/3a/103af168-bb96-4959-b138-c3f16d5e5253/content/images/size/w2000/2023/08/Screenshot-2023-08-20-at-8.10.24-PM.png)
이번주 사내 테크 세미나에서 이 논문을 리뷰해서 발표했다. CRS의 전반적인 내용과 어떻게 LLM을 이용하여 접근해야할지 잘 알려준 논문이라고 생각하고 개인 블로그에도 논문에 대한 내용을 기반으로 몇 자 적어볼까 한다.
CRS가 무엇인가요?
Conversational Recommender System (CRS) 는 유저와 Conversation 을 통해 추천 서비스를 제공하는 시스템을 말한다. 우리가 살아가면서 가장 흔히 접할 수 있는 추천 서비스는 온라인 리테일 매장에서 볼 수 있다.
쿠팡을 들어가보면 위와 같이 내가 이전에 조회했던 상품들을 기반으로 추천을 해준다. 유저가 따로 추천을 요청하지 않아도 알아서 적당한 상품을 추천해주는 것이다. 이런 user-passive 한 추천이 아닌 우리는 가끔 적극적으로 우리의 선호를 드러내어 추천을 받고 싶어한다. 이처럼 유저와의 소통을 통해 추천이 이뤄지는 것이 CRS라고 보면 된다.
CRS에는 2가지 종류가 있다.
- Attribute-based CRS: 어느 정도 정해진 질문이 있고, 그 질문을 토대로 유저의 속성을 파악하여 추천을 해주는 방식이다. 이 CRS의 장점으로는 input의 형식이 어느 정도 정해져 있고, feature 또한 explicit 하게 알아낼 수 있기에 좋은 모델을 개발하는 데 유리하다. 하지만, 유저가 모델에게 맞춰서 input을 줘야 하는 번거로움이 있다. Ex, 20대 / 남성 / 3만원 이하 / 셔츠 로 추천해드릴게요!
- Generation-based CRS: 유저가 보다 자유롭게 자연어를 사용해서 추천을 받아낼 수 있다. 유저가 편하게 말한 input을 모델이 잘 이해하고 중요한 feature 들을 찾아내서 추천해줘야 한다. Ex, 어 난데, 가성비 좋은 셔츠 하나 추천해줘. 지금 내가 가지고 있는 옷들하고 색상은 비슷하게 말이야.
UX 관점에서 Generation-based CRS 가 유리한 반면, 현 시장에서는 거의 모든 CRS들이 Attribute-based CRS 로 이뤄지고 있다. 왜냐하면, User의 무궁무진한 Input 을 제대로 이해하고 좋은 추천을 하기에는 아직 인공지능 분야가 덜 발전했기 때문이다.
However! LLM이 등장하고 나서는 이전보다 더 가능성을 재고해볼 수 있게 되었다. LLM의 장점이 Natural Language Understanding, 즉 유저의 input에 담겨진 의도를 잘 이해할 수 있다는 것이다. 이런 LLM을 CRS에 적용하려는 시도들이 이뤄지고 있다.
CRS가 해내야 하는 4가지 역할
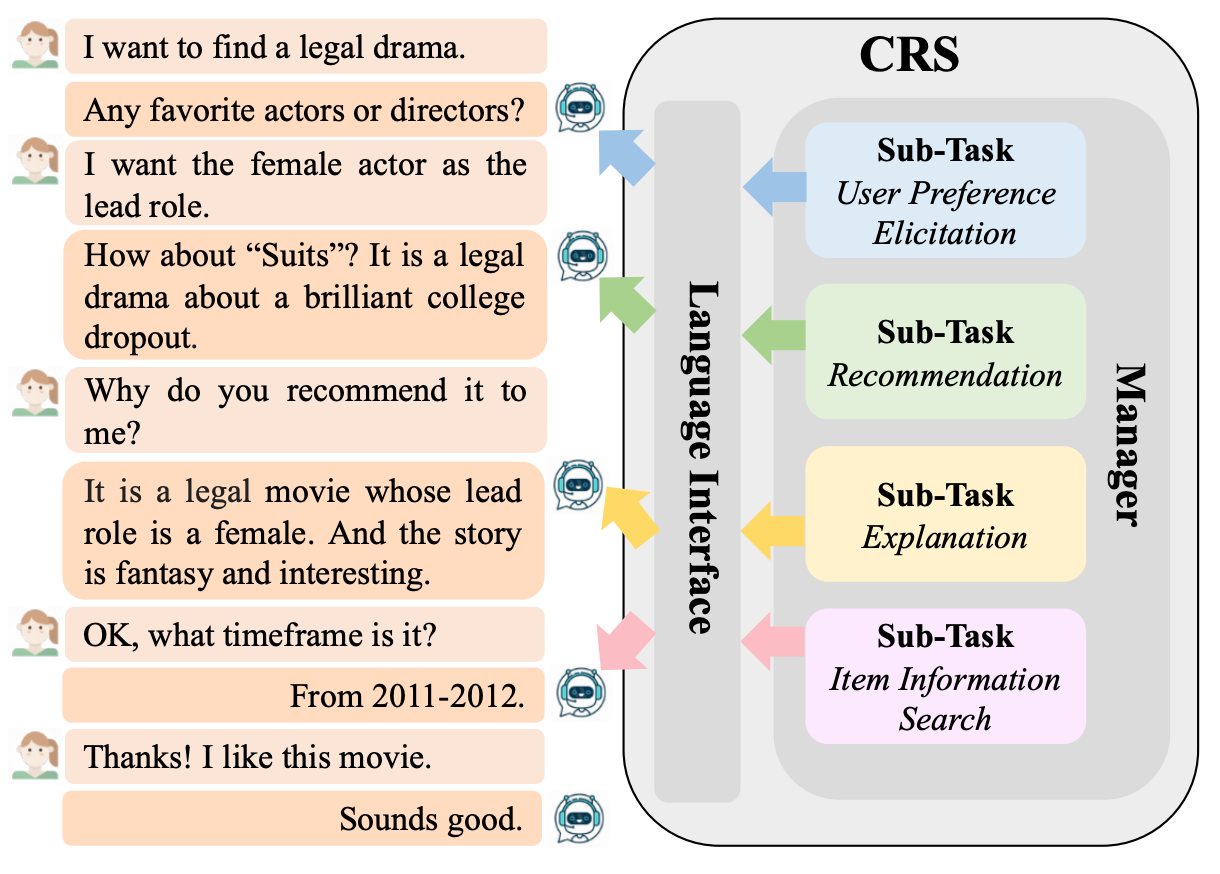
- User Preference Elicitation: 유저의 취향을 알아내야 한다. 제대로 된 추천을 할 수 있을 정도로 유저의 정보를 물으며 답변을 통해 추천에 좋은 feature 들을 추출해낸다.
- Recommendation: 유저의 취향에 적절한 Item을 추천한다!
- Explanation: 추천한 Item을 왜 추천하였는지 설명할 수 있어야 한다. UX 관점에서 explanation을 중요한 역할 중 하나라고 생각한다. 그저 추천만 하고 유저가 이유를 알 수 없다면, 정말 내 취향을 잘 파악해서 추천을 한건지 그냥 대충 한건지 모르기 때문이다. 특히, AI를 사용한 서비스의 경우, truthfulness를 가져야 경쟁력이 있다. ChatGPT에서 문제가 되는 것 중 하나가 Hallucination이기에 사람들은 AI가 헛소리를 할 수 있다는 가능성을 다 알고 있다. AI와 사람 간의 신뢰가 없는 현재로서는 AI가 더 노력을 해야 한다. 더 잘 설명해줘야 한다.
- Item Detail Search: Item에 대한 구체적인 정보를 유저가 원할 때, 제공할 수 있어야 한다.
CRS의 Workflow
실제로 유저가 서비스에게 말을 건넬 때부터, 답변을 받을 때까지의 workflow 를 살펴보자. LLMCRS의 Workflow는 총 4단계로 이뤄져 있다.
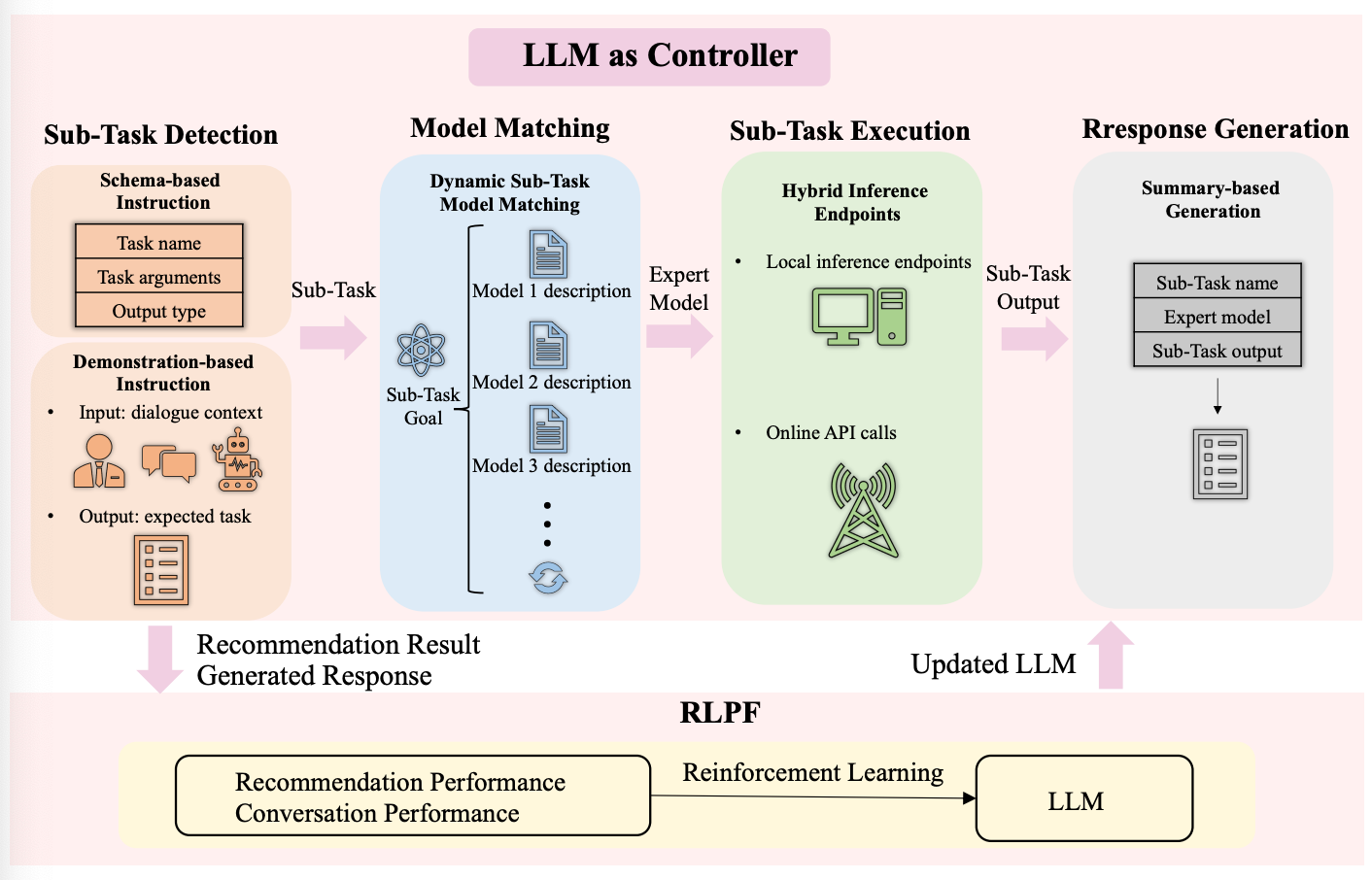
- Sub-Task Detection: 앞서 CRS가 해내야 할 4가지 역할에 대해 살펴보았는데, 실제로 유저와 소통할 때, 어떤 Task를 실행해야 하는지 detection을 해야 한다. 예를 들어, 유저에 대한 정보가 부족하다면, User prefence Elicitation Task를 수행해야 할 것이고, 유저가 추천받은 상품에 대해 가격이나 사이즈를 물어본다면, Item Detail Search Task를 수행해야 할 것이다. 이 Detection에 LLM을 활용하여 수행된다.
- Model Matching: 각 Task를 수행할 Model 들이 특정 List에 모여있을텐데, 앞 단계에서 어떤 Task를 수행할지 정해졌다면, 그 Task에 맞는 Model 또한 찾아줘야 한다. 이는 Task description과 model description을 matching 하는 식으로 LLM을 활용하여 수행된다.
- Sub-Task Execution: 어떤 Task를 수행할지, 어떤 모델로 수행할지 정해졌다면 실제로 수행을 하는 단계다.
- Response Generation: 모델이 출력한 output을 LLM이 잘 다듬어서 유저에게 보낼 답변을 만든다.
앞으로 CRS를 개발한다면, 어떤 Task 들이 있는지, 어떤 Workflow 대로 흘러가는지 감을 잡는데 도움이 될 수 있는 논문이라고 생각한다. 논문 후반에는 실제로 데이터셋을 가지고 LLMCRS를 평가했는데 기존 CRS 모델들 보다 좋은 성능을 보여줬다고 한다!
참고로 요즘 내가 인상깊게 읽은 LM 논문을 정리해서 매주 금요일 저녁마다 뉴스레터를 발행하고 있다. 이 논문 또한 이번주 뉴스레터의 2번째 논문으로 속해 있다. 관심있는 사람들은 아래 링크를 참고하면 좋을 것 같다. :)
