[Paper Review] Code Llama: Open Foundation Models for Code

![[Paper Review] Code Llama: Open Foundation Models for Code](https://images.unsplash.com/photo-1640441281085-9e2000f3d693?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDV8fG1ldGF8ZW58MHx8fHwxNjkyOTc2MjM3fDA&ixlib=rb-4.0.3&q=80&w=2000)
어제 Meta에서 Llama-2, SeamlessM4T에 이어 Code Llama라는 엄청난 모델을 공개하였다. 요즘 매일 Arxiv에서 LLM 논문 찾아보는 사람으로써 Meta 만큼 열심히 리서치하는 곳 없는 것 같다.
아무튼 이 논문이 세상에 공개되자마자 나도 열심히 읽어보았고, 아직 읽어보지 않은 사람들에게 조금이나마 도움이 될까 싶어서 주관적으로 논문에서의 핵심을 뽑아 정리해보겠다.
결론부터 얘기하자. Code Llama 쓸만한가?
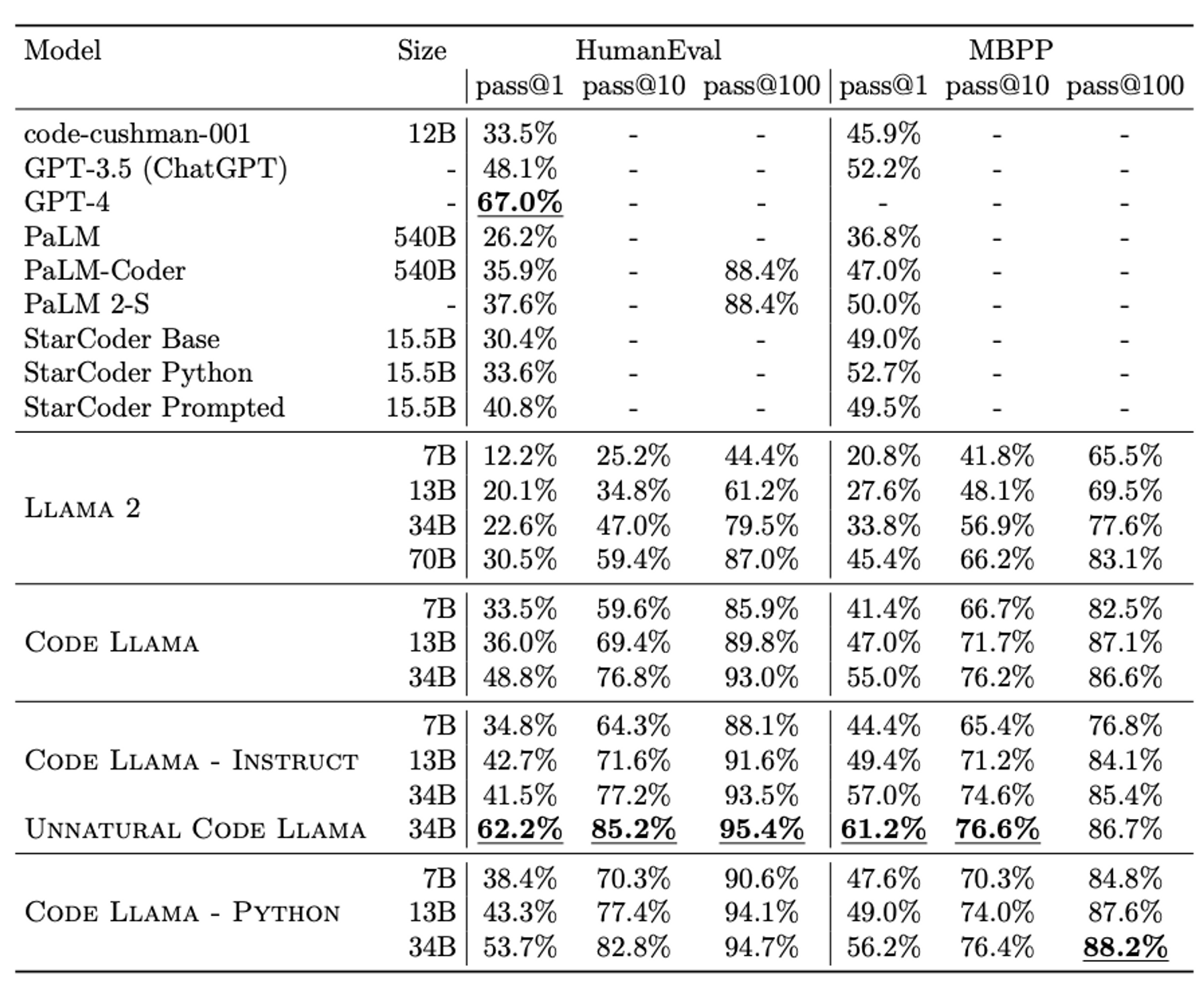
표를 보다시피 Unnatural Code Llama의 경우, HumanEval pass@1 값이 GPT-4 만큼 나온다. 전반적으로 기존에 있었던 모델들 (StarCoder, ChatGPT) 와 유사하거나 더 나은 성능을 보여주고 있기 때문에, Code Llama 를 사용해서 꽤 경쟁력 있는 서비스를 만들 수 있다고 생각한다.
이제 Meta가 어떤 식으로 Code Llama를 만들었는지 살펴보자.
배경지식
사실 깊게 들어가기 전에 중요한 3가지 개념을 짚고 가면 좋겠다.
Causal Masking
Causal Masking 이란, 위에 첨부한 논문에서 가장 처음으로 제시된 LM의 training objective 방식으로, text 중간을 마스킹하고 그 마스킹된 문장을 제일 뒤로 보내서 next token prediction 하는 식으로 학습한다.

2022년 4월, FAIR가 Code Generation을 위해 만든 InCoder라는 모델에서도 이 방식으로 학습을 진행하였고 그 이후로도 계속 쓰이고 있는 방법이다.
Fill-in-Middle (FIM) training
문장을 세 조각 내어서 prefix, middle, suffix로 분리를 하고 tokenization을 다음과 같이 한다.
<Pre> - prefix - <SUF> - suffix - <MID> - middle - <EOT>
이렇게 데이터셋을 만들고 학습하게 되면, 이 또한 이전에 봤던 것처럼 text 중간을 잘 학습하도록 유도된다. Code-level로 이해하고 싶은 사람들을 위해 Code 또한 첨부하겠다.
def character_level_psm_fim(document: str, vocab: Vocab) -> List[int]:
prefix, middle, suffix = randomly_split(document)
return [
vocab.sentinel("prefix"), *vocab.encode(prefix),
vocab.sentinel("suffix"), *vocab.encode(suffix),
vocab.sentinel("middle"), *vocab.encode(middle),
]Rotary Position Embedding (RoPE)
Transformer 자체는 문장 내의 각 token의 위치 정보를 알지 못한다. 그래서 우리는 token 마다 position 정보를 잘 embedding 해줘야 한다. 지금은 잘 사용하지 않지만 가장 대표적이었던 positional embedding 기법으로는 Transformer 모델 논문에서 소개된 sinusoidal embedding이 있겠다. 근데 이건 너무 오래되었고 absolute 하기에 요즘처럼 가변적이고 long context를 다루기에는 부적절해서 잘 사용하지 않는다.
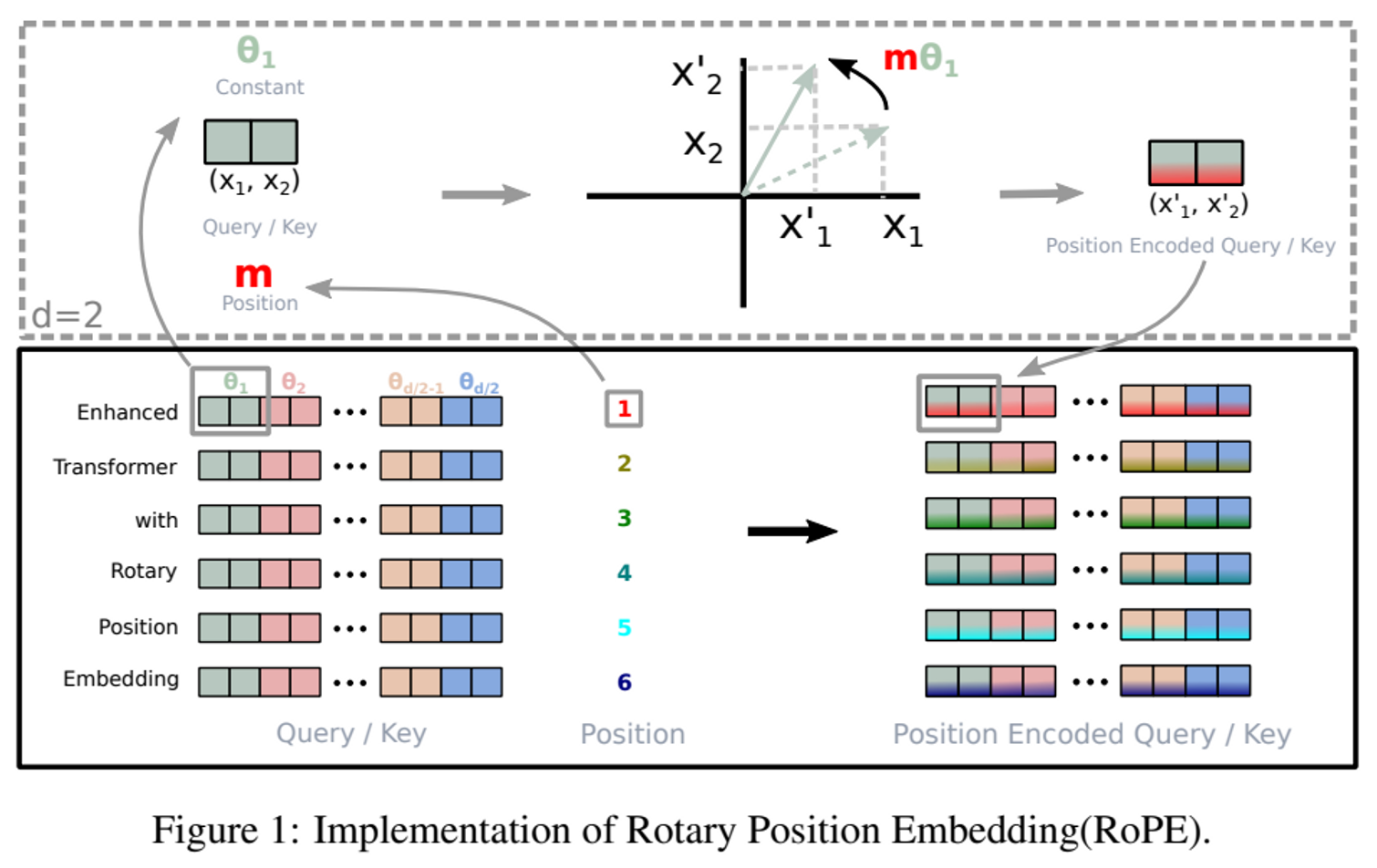
RoPE는 absolute position 을 Rotation Matrix를 통해 인코딩하고 self-attention 을 이용해 relative position 값을 계산하여 둘을 모두 사용하는 방식이다. RoPE를 100% 잘 알고 있지는 않지만 아무튼 RoPE는 flexible 하기에 sequence의 token 수를 키워도 추론을 잘해낸다. 다시 말하자면, train data는 context length가 1K token 이어도, inference 시에 context length를 10K 까지 키워서 추론 가능하다는 것이다. 그래서 요즘에는 이런 RoPE와 Alibi가 Positional Embedding에서 가장 많이 쓰이는 기법이다.
어떤 데이터로 어떻게 학습시킨걸까?
이제는 조금 더 깊게 Code Llama를 어떻게 만들었는지 알아보도록 하자. 우선 모델은 Llama 2와 완전히 동일하다. Llama 2에 추가적인 데이터로 추가적인 학습을 해서 만들어진게 Code Llama다.
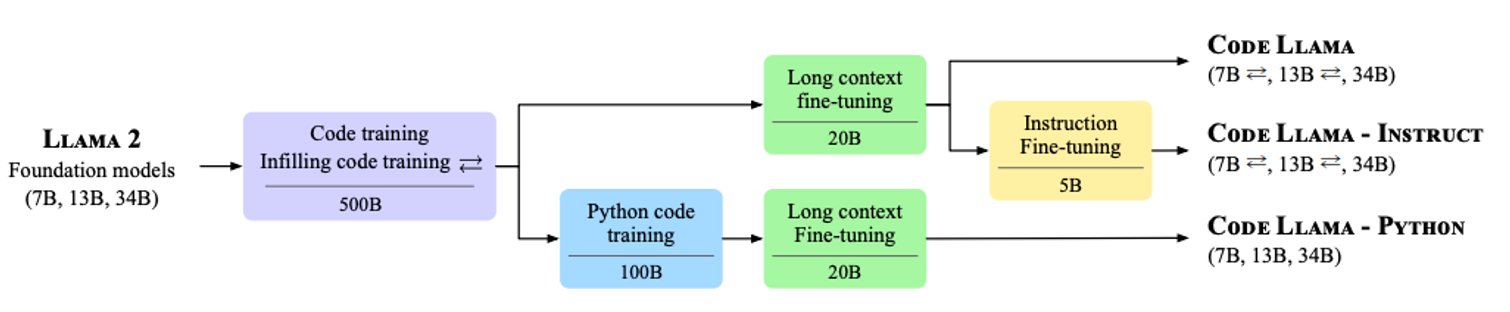
그림을 보다시피 이번에 공개한 모델은 총 3가지다. Code Llama, Code Llama - Instruct, Code Llama - Python. 이 모델을 만들기 위해 총 4가지 학습 방법이 소개되었다. 하나씩 살펴보자.
Code training / Infilling code training

500B에 달하는 데이터로 Llama 2를 학습하여 Code Llama를 만들었다. 데이터를 살펴보면, Code 가 아닌 Natural language 관련 데이터도 15% 있는데 우리가 이 모델을 그저 Code를 작성하도록 사용할 것이 아니라 자연어를 통해 소통할 것이기에 필요했다고 생각한다. Tokenizer는 Llama와 Llama 2 때와 동일하게 Byte-Pair Encoding Tokenizer를 사용하였다.
학습 방식은 앞서 보았던 Fill-in-Middle 학습 방법을 7B, 13B에 대해서 적용하였다고 한다. 34B 모델에 대해서는 왜 적용하였는지 찾아내진 못하였다.
Long context fine-tuning (LCFT)
긴 input에 대해서도 성능이 잘 나오기 위해서 long context fine-tuning을 해주었다. text 가 길어질 때 가장 핵심적으로 봐야할 부분은 positional embedding이다. 이 논문에선 RoPE 임베딩을 사용하였고, fine-tuning 시에는 기존 Llama 2에서 사용하던 rotation frequency, θ 값을 10,000 에서 1,000,000 까지 키웠다.
RoPE의 Rotation frequency를 여기서 설명하기엔 내용이 길어질 것 같아서 생략하겠다. 논문에서는 이 값을 키워주는 것이 long context에 대해서 성능을 향상시키는 데 큰 도움이 되었다고 하였다.
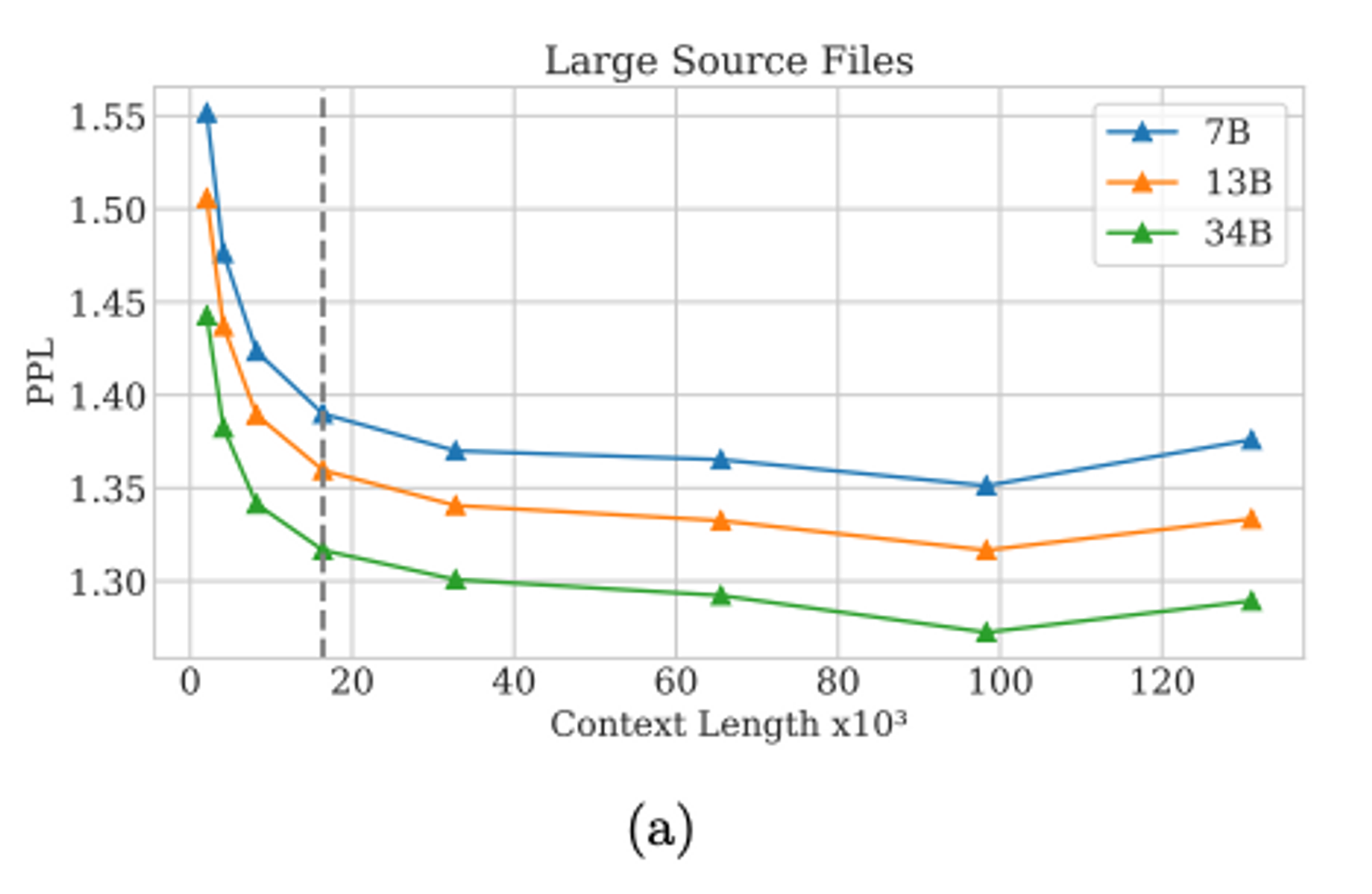
Context Length가 긴 데이터에 대해 Perplexity를 측정한 그래프를 보면, 100K token 까지 PPL이 안정적으로 하락하는 것을 볼 수 있다.
Python code training
Code Llama - Python 모델은 특별히 Python Code가 엄청 많은 100B 데이터셋으로 fine-tuning을 해주었다. 이때는 따로 FIM 기법을 사용하지 않았다고 한다.
Instruction Fine-tuning
Data는 Llama 2 때 instruction tuning을 위해 사용한 데이터셋을 동일하게 사용하였는데, 또한 추가적으로 self-instruct 라는 기법을 사용해서 14,000 개 정도 데이터를 수집하였다.
self-instruct 기법은 다음과 같다. 아래서 말하는 Prompt는 모두 논문 Appendix에 있으니까 궁금하면 직접 봐보는 것도 좋겠다.
- Prompt 를 사용해서 Llama 2 70B를 통해 62,000 개의 interview-style 질문 프로그래밍을 만든다.
- 62,000 개의 데이터 중 겹치는 질문들을 제거해준다. (De-duplication) 52,000 개 데이터가 살아남았다.
- 각 데이터에 대해, Prompt 를 사용해서 Code Llama 7B 로 unit test code와 10개의 Python solution을 만든다. 그리고 10개의 solution에 대해 unit test를 돌려서, 처음으로 unit test를 통과한 solution을 데이터셋에 추가한다.
여기서 더 성능이 좋은 34B 모델이 아닌 7B 모델을 사용한 이유는 동일한 compute budget이 있을 때, 7B 모델을 사용하는 것이 더 효율적이라고 판단했다고 한다.
요즘 이렇게 자체적으로 data augmentation을 하는 기법들이 많이 나오고 적용되고 있는 것 같다.
Training Details
위 논문에서 요즘 거의 모든 모델이 Adam, AdamW를 사용하고 있다고 했는데 Code Llama 또한 AdamW를 사용하였고 그 안에 beta_1, beta_2도 가장 많이 사용하는 0.9, 0.95 를 사용하였다.
Unnatural Code Llama는 뭔데 GPT-4 만큼 잘해?
이 모델은 Code Llama - Python 34B를 15,000 개의 unnatural instruction 에 대해 fine-tuning 한 것이다.
위 논문에서 제안된 Unnatural Instructions 이라 함은, 인간의 노동 없이 LM 한테 prompting 만 잘해서 수집한 instruction data를 말한다.
그런데 아쉽게도 이 모델은 release 하지 않았다. safety에서 문제가 생긴걸까?
Responsible AI and safety
Llama 2 처음에 나왔을 때, Meta는 AI safety를 중시하여 모델을 개발하였다고 전했고 실제로 타 모델들보다 safety 측면에서 좋은 성능을 보였다.
이번에 Code Llama를 개발할 때도 Truthfulness를 위해선 TruthfulQA를, Toxicity를 위해선 ToxiGen을 Bias를 위해선 BOLD 데이터셋을 사용하였다.



25명으로 Red team도 구성해서 모델이 유저의 나쁜 행위 (Ex, 폭탄은 어떻게 제조할 수 있어?) 를 도와주는지 점검을 하였다고 한다.
Conclusion
이 논문을 읽으면서 느꼈던 건 갈수록 LLM 서비스를 개발할 때는 Data 확보가 가장 중요하겠다는 것이다. Model Architecture는 큰 변화가 없는 것 같고, Foundation Model 이라는 개념도 나오는 시대에서 우리가 집중해야될 부분은 Data라고 생각한다. 좋은 Quality 이면서 방대한 양의 Data를 가지며, 리소스를 가지고 있다면 세상에 임팩트 있는 모델을 개발해낼 수 있을 것이다. 게다가 앞서 봤던 self-instruct 방법처럼 LLM 등장 이후 Data 수집에 있어서 인간의 개입이 점점 줄어들고 있다. 보다 쉽게 좋은 Data를 가질 수 있는 환경이 계속해서 오는 것 같아 진입 장벽이 낮아지는 느낌이다.
그러면 Data 다음으로는 어떤게 중요할까? 사실 남은 키워드는 하나인 것 같다. 어떻게 학습을 할 것인지가 중요하다. reward model을 개발할 건지, Positional Embedding은 어떤 걸 사용할지 등등 학습에 필요한 세부적인 사항들을 직접 모두 알고 어떤 상황에서 어떤게 좋은지 파악하고 있어야 한다. 그리고 필요하면 바로 직접 코드를 개발해서 모델을 돌릴 수 있을 정도의 엔지니어링 실력도 받쳐줘야 된다.
나는 이런 쪽으로 계속 공부해나가려고 한다. 세상에 임팩트를 내는 모델을 개발하기 위해서!